
SQLAlchemy یک کتابخانه طراحی شده برای کار با پایگاه های داده SQL است که از گویش های مختلف مانند MySQL، PostgreSQL، SQLite و غیره پشتیبانی می کند. در مورد ما، از PostgreSQL – یک پایگاه داده SQL به خوبی تثبیت شده استفاده خواهیم کرد.
SQLAlchemy دو نسخه ارائه می دهد: Core که می توانید به عنوان سازنده پرس و جو فکر کنید و ORM که ترجیح داده می شود.
ما گزینه های زیادی برای استفاده از PostgreSQL داریم – در ابر یا در ماشین محلی شما. ما از Docker استفاده خواهیم کرد زیرا نیاز به نصب دستی را از بین می برد و تنها با چند خط کد امکان تغییرات آسان در پیکربندی را فراهم می کند.
نصب وابستگیها
وابستگی ها را نصب کنید
ما از و آخرین نسخه SQLAlchemy (در حال حاضر 2.0.20) استفاده خواهیم کرد. python-dotenv به ما کمک می کند تا متغیرها را از متغیرهای محیط بارگیری کنیم. می توانید چندین محیط ایجاد کنید و محیط مورد نیاز خود را بارگذاری کنید.
pip install "psycopg[binary]"
pip install SQLAlchemy
pip install python-dotenvSetup
ساختار پوشه
.env file
یک فایل env ایجاد کنید. در صورت تمایل می توانید مدارک خود را انتخاب کنید.
DB_USERNAME=admin
DB_PASSWORD=123456
DB_NAME=medium_dbPostgres با Docker
این فایل docker-compose.yml ما است.
version: '3.8'
services:
postgres:
restart: 'always'
image: postgres:15.4-alpine
networks:
- db
volumes:
- ./todo.sql:/docker-entrypoint-initdb.d/schema.sql
env_file:
- .env
environment:
- POSTGRES_DB=${DB_NAME}
- POSTGRES_USER=${DB_USERNAME}
- POSTGRES_PASSWORD=${DB_PASSWORD}
healthcheck:
test: [ "CMD-SHELL", "pg_isready -U ${POSTGRES_USER}" ]
timeout: 2s
interval: 5s
retries: 10
ports:
- 5432:5432
adminer:
image: adminer
restart: always
ports:
- 8080:8080
networks:
- db
networks:
db:با استفاده از این دستور می توانید فایل را اجرا کنید
docker-compose -f docker-compose.yml up -d
می توانید به Adminer در http://localhost:8080 دسترسی داشته باشید. اگر از Docker استفاده می کنید، از این رمز عبور استفاده کنید: 123456 (یا شما).

ارتباط
ما اعتبارنامه ها را از فایل .env بازیابی می کنیم و URL را برای ایجاد ارتباط با پایگاه داده خود ارسال می کنیم. فعال کردن پرچم echo در طول توسعه مفید است زیرا SQLAlchemy کوئری های SQL را که ما اجرا می کنیم ثبت می کند. تابع create_engine یک مخزن اتصال با کمک DBAPI ایجاد می کند.
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker, declarative_base
from dotenv import dotenv_values
Base = declarative_base()
def db_connect():
config = dotenv_values("./.env")
username = config.get("DB_USERNAME")
password = config.get("DB_PASSWORD")
dbname = config.get("DB_NAME")
engine = create_engine(f"postgresql+psycopg://{username}:{password}@localhost:5432/{dbname}", echo=True)
connection = engine.connect()
return engine, connection
db_connect()ایجاد/حذف جداول
اگر می خواهید جداول را بر اساس طرح های تعریف شده ایجاد کنید، می توانید از تابع create_all استفاده کنید. از سوی دیگر، drop_all در طول توسعه کاربردی است، به خصوص زمانی که مفاهیم جدیدی را یاد می گیرید یا تغییراتی ایجاد می کنید که ممکن است منجر به خروج های پیچیده شود.
با این حال، مهم است که توجه داشته باشید که drop_all برای محیط های تولید مناسب نیست، زیرا منجر به حذف داده های تولید می شود، چیزی که ما می خواهیم از آن اجتناب کنیم.
def create_tables_orm(engine):
Base.metadata.drop_all(engine, checkfirst=True)
Base.metadata.create_all(engine, checkfirst=True)جلسه
یک جلسه برای تداوم یا واکشی داده ها از پایگاه داده استفاده می شود.
def create_session(engine):
Session = sessionmaker(bind=engine)
session = Session()
return sessionایجاد جدول
ابتدا باید طرح پایگاه دادهی خود را تعریف کنیم. باید مدلهای پایگاه دادهی خود را با وضعیت فعلی در پایگاه داده همگام کنیم. اگر این کار را انجام دهیم،می توانیم با خیال راحت با اشیاء موجود در کدمان کار کنیم.
from sqlalchemy import Column, Text, Integer
class Products(Base):
__tablename__ = "products"
product_id = Column(Integer, primary_key=True)
low_fats = Column(Text, nullable=False)
recyclable = Column(Text, nullable=False)
create_tables_orm(engineپس از اجرای کد، جدول ما ایجاد خواهد شد.

درج داده
باید طرح پایگاه دادهی خود را تعریف کنیم. حفظ هماهنگی مدلهای پایگاه دادهی ما با وضعیت فعلی پایگاه داده بسیار مهم است.
با انجام این کار، میتوانیم به امانت با اشیاء در کد خود کار کنیم – ایجاد یک شی جدید، نقشهبرداری اشیاء و غیره.
فراموش نکنید که session.commit() را اضافه کنید. بدون این کار، کد بدون مشکل اجرا میشود اما دادهها در پایگاه داده ذخیره نخواهند شد.
new_products = [
Products(low_fats="Y", recyclable="N"),
Products(low_fats="Y", recyclable="Y"),
Products(low_fats="N", recyclable="Y"),
Products(low_fats="Y", recyclable="Y"),
Products(low_fats="N", recyclable="N"),
]
session.add_all(new_products)
session.commit()این اقدام باید به درج داده های جدید در پایگاه داده منجر شود.
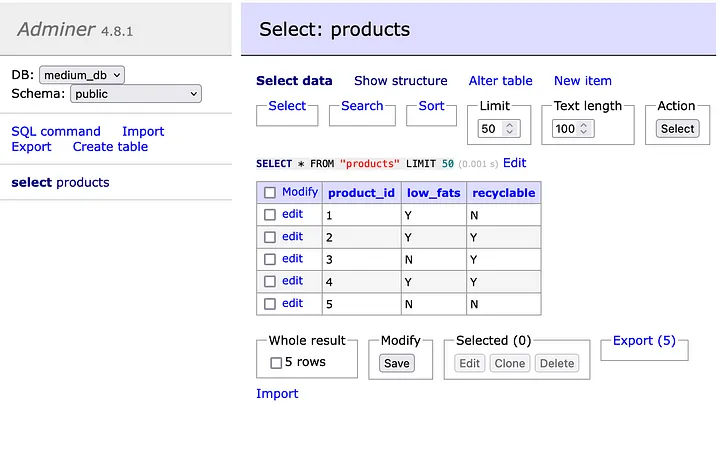
داده ها را انتخاب کنید
ما میخواهیم این پرسوجو را در پایگاه دادهی خود اجرا کنیم.
SELECT p.product_id
FROM products p
WHERE p.low_fats = 'Y' AND p.recyclable = 'Y';همانطور که مشاهده میکنید، این کار بسیار ساده است. شما میتوانید تشابههای زیادی با پرس و جوهای SQL اصلی پیدا کنید.
from sqlalchemy import Column, Text, Integer, and_ # new
result = session.query(Products.product_id).where(and_(Products.low_fats == "Y", Products.recyclable == "Y"))
for row in result:
print(row.product_id)
# 2
# 4
session.close()
connection.close(کد: مخزن Github
از اینکه برای مقاله من وقت گذاشتید و خواندید متشکرم از علاقه شما به موضوع تشکر می کنم و امیدوارم آموزنده بوده باشد. اگر نظر یا پیشنهادی در مورد مقاله دارید،لطفاً با ما به اشتراک بزارید


